
OpenAI发布了名为DALL-E 2的新版本AI程序,它使用自然语言描述来生成逼真的艺术图像,但是该技术也引发了一些担忧,包括可能对艺术家和NFT市场造成冲击。该程序将由经过审查的合作伙伴测试,并且不会向公众开放。此外,OpenAI表示将确保DALL-E 2不会用于制作有害或淫秽的图像,并且将尽可能防止其造成进一步的破坏。
具体了解DALL-E 2
DALL-E 2是一种基于语言的人工智能图像生成器,可以根据文本提示创建高质量的图像和艺术作品。它是DALL-E的升级版,分辨率和字幕匹配都有所提高。DALL-E 2使用CLIP、先验和unCLIP模型来生成图像,其质量取决于文本提示的具体性。它在准确地组合多个对象属性方面存在局限性。DALL-E 2为创造和消费艺术开辟了新的可能性和挑战,虽然它有可能重新定义艺术,但也有可能影响创意产业。
什么是CLIP先验和unCLIP?
CLIP先验和unCLIP是DALL-E 2图像生成器使用的两个模型。
CLIP(Contrastive Language-Image Pre-Training)先验模型基于自然语言和图像编码器,通过对大量图像文本对集合进行训练,生成文本/图像嵌入矢量表示。它为DALL-E 2生成器提供了对输入文本的理解,从而控制图像的主题、风格、角度、背景、位置和概念。
unCLIP是一种解码器扩散模型,通过CLIP图像嵌入生成原始图像,它使用扩散学习来创建“心理”图像表示。这些“心理再现”保留了语义一致的核心特征和特点,例如动物、物体、颜色、风格和背景等关键要素。然而,因为扩散学习是变化的,每一次输出的图像也会有所不同。
CLIP先验和unCLIP模型结合使用,使DALL-E 2能够更好地理解文本提示,并生成高质量的图像和艺术形式。
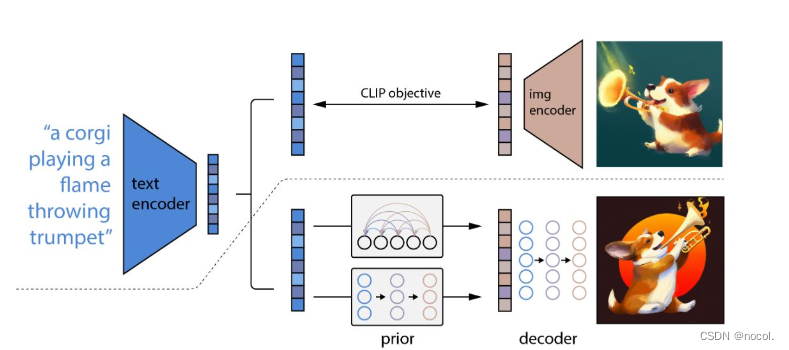
什么是encoder 和 decoder
有些人可能会问什么是这个图里面的 encoder 和 decoder
Encoder 是指将输入文本描述编码为数字化的特征表示的网络层。在 DALL-E 中,这些特征向量可以看作是文本描述的“概念表示”,它们捕捉了输入描述中的重要语义概念,例如颜色、形状、材质和场景等。
Decoder 是指将这些特征向量解码为图像的网络层。在 DALL-E 中,decoder 接收编码后的特征向量作为输入,并将其转换为生成的图像。换句话说,decoder 是根据 encoder 的编码特征,生成对应图像的模型。
通过将 encoder 和 decoder 结合在一起,DALL-E 可以将自然语言文本描述转换为对应的图像表示。这种文本到图像的转换是基于深度神经网络的生成模型实现的,这些模型通过训练学习了如何从语言中理解图像的各个方面,并能够生成高质量的图像。
总结而言, DALL-E使用文本描述来生成图像。它包括三个主要组件:文本编码器、图像编码器和解码器。文本编码器将文本描述编码成一个向量表示,图像编码器将原始图像编码成一个向量表示,解码器将这两个向量表示结合起来生成新的图像。同时,DALL-E 2 使用了 CLIP、prior 和 unCLIP 模型来提高生成的图像的质量和准确性。
什么是CLIP Objective
CLIP Objective是指对比语言图像预训练的目标函数,之前已经提到, CLIP是DALL-E中的一个关键组成部分。他的目标目标函数用于训练CLIP模型,它可以让机器学会如何理解自然语言和视觉图像之间的关系。CLIP模型是一种多模态神经网络(后面我会解释), 可以将自然语言文本和图像转化为相同的嵌入向量空间,使得相似的文本和图像在这个向量空间中距离更近。通过学习这种距离关系,CLIP模型可以判断文本描述和图像是否相符,从而实现图像分类、图像搜索和图像生成等任务。CLIP Objective的设计非常重要,它的合理性和有效性直接影响了CLIP模型的性能。
关于多模态神经网络
在计算机视觉和自然语言处理中,多模态(multimodal)是指结合多种信息来源(例如图像、音频、文本等)的方法。在CLIP中,使用了一种多模态神经网络结构,可以同时处理图像和文本输入,从而能够将两者联系起来,实现跨模态的任务。
具体来说,CLIP中的多模态神经网络由两个部分组成:图像编码器(image encoder)和文本编码器(text encoder)。图像编码器将图像转换为向量表示,文本编码器将文本转换为向量表示,两个向量表示可以相互匹配,即将图像和文本语义相关联起来。
多模态神经网络的训练方式是基于对比损失(contrastive loss),即将匹配的图像和文本向量靠近,不匹配的图像和文本向量拉远。通过这种方式,多模态神经网络可以学习到图像和文本之间的相似性,从而能够更好地理解跨模态任务中的输入数据,如图像标注、图像检索等。
我们再来解释下嵌入向量空间.
什么是嵌入向量空间
在 CLIP 中,嵌入向量空间是指文本和图像被转化为嵌入向量的高维空间,文本和图像分别被映射到该空间中的不同位置。嵌入向量是由神经网络学习得到的低维度表示,它捕捉了文本和图像之间的语义信息和关系。因此,在嵌入向量空间中,相关的文本和图像通常会被映射到相似的位置,使得它们之间的相似性得以计算。嵌入向量空间的概念是 CLIP 模型成功的关键之一,因为它允许 CLIP 模型基于嵌入向量的相似性来对文本和图像进行匹配,从而实现多模态任务,例如图像分类和文本检索。
串在一起
我们回头来吧这些概念总结一下.
